High availability and disaster recovery
When you deploy a database cluster in a production environment, multiple replicas are created to ensure high availability and data durability. If the traditional deployment method is used, one primary node and one secondary node are deployed. Logs are used to synchronize data changes between the primary node and the secondary node. However, primary and secondary replication has inherent problems. For example, for semi-synchronous replication that is supported by MySQL, if the network latency exceeds the threshold, synchronous replication degenerates to asynchronous replication. During this period, if the primary node stops responding, data that is committed may not be transmitted to replicas. In this case, data is inconsistent among the replicas.
To ensure strong consistency among replicas, modern databases often use a majority consensus protocol represented by Paxos for data replication. In most cases, Paxos requires at least three nodes in a cluster. Each time the cluster performs a write operation, the write request must be accepted by more than half of the nodes. This way, even if one of the nodes stops responding, the cluster can still provide services in a normal manner. Paxos can ensure strong consistency and eliminate inconsistency issues among replicas.
PolarDB-X uses X-Paxos to synchronize data to replicas. X-Paxos is developed by Alibaba Cloud to implement Paxos. X-Paxos is based on AliSQL, which is a MySQL branch in Alibaba. X-Paxos provides optimized features and enhanced performance based on Paxos. X-Paxos has provided reliable and highly available services to ensure business stability during peak hours of the Double 11 shopping festival for more than 10 years.
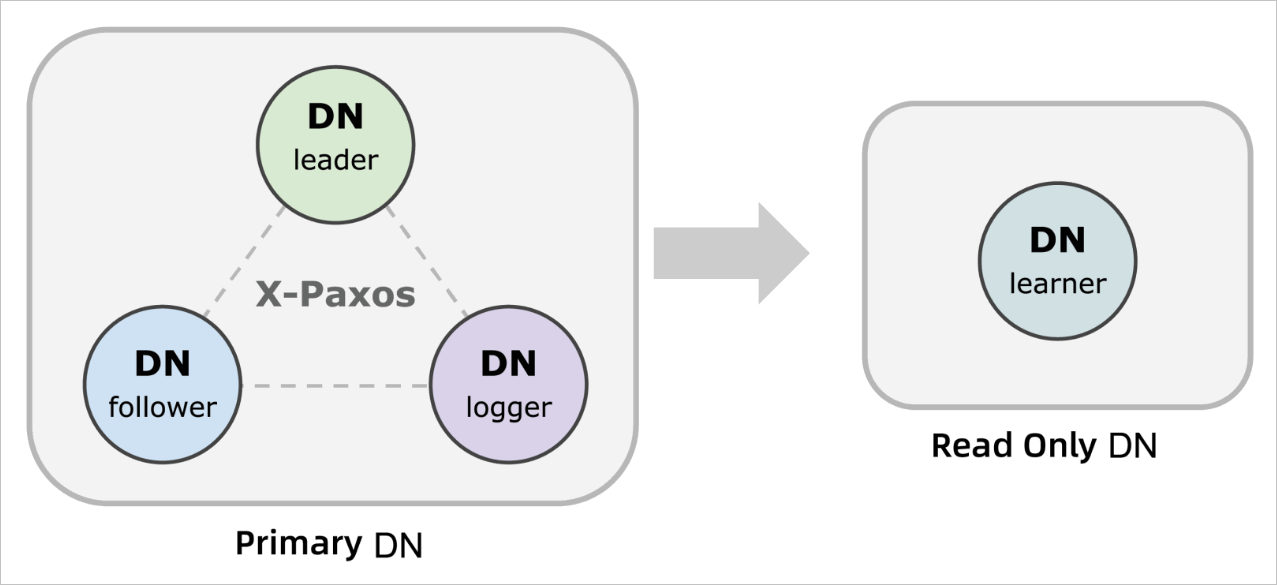
X-Paxos implements the multi-Paxos algorithm. In most cases, a stable leader is available to process read and write requests. If the leader stops responding to a request from a follower or a request from a follower times out, the follower initiates the process to select a leader again. If a node receives more than half of the votes, the node becomes the new leader. A logger is responsible only for saving log information and participating in the leader election. In most cases, a learner is deployed in a read-only instance. A learner only receives log information about data changes from the primary instance. A learner does not participate in the leader election.
X-Paxos also provides enterprise-grade features that allow you to deploy PolarDB-X instances based on your business requirements. For example, you can dynamically add or remove nodes, configure weighted leader election, and configure the leader to automatically perform failback operations.
Multi-data center deployment
PolarDB-X instances can be deployed in multiple data centers to implement disaster recovery based on data centers. Common deployment methods include three data centers in the same zone and three data centers across two zones. The second method is used in hybrid cloud deployment scenarios. In most cases, one of the three data centers functions as the primary data center due to the characteristics of the Paxos protocol. The primary data center is responsible for providing external services.
Active geo-redundancy
If your business has requirements for active geo-redundancy, we recommend that you deploy PolarDB-X instances across regions and connect the instances by using data synchronization tools, such as Data Transmission Service (DTS). This way, instance performance is ensured. Data must be split into different partitions based on your business requirements. This ensures that no conflicts exist between data in different regions. The global data change logging feature provided by PolarDB-X allows you to synchronize data between instances.