HTAP
PolarDB-X supports hybrid transaction/analytical processing (HTAP). PolarDB-X supports highly concurrent requests, transactional requests, and analytical queries.
Note Analytical queries are performed on large amounts of data and require complex computations. For example, you can perform analytical queries to aggregate data within a specific period of time. Compared with common simple queries, analytical queries require a longer period of time to execute and consume more computing resources. It takes several seconds or minutes to execute an analytical query.
To accelerate complex analytical queries, PolarDB-X splits each computing task and assigns the subtasks to multiple compute nodes. This way, you can use the computing capabilities of multiple nodes to accelerate query execution. This request processing method is known as massively parallel processing (MPP). By default, only read-only PolarDB-Xinstances support MPP.
Query optimizers
The optimizer of PolarDB-X is developed to handle HTAP workloads and can provide services for complex queries. In a Transaction Processing (TP) query, the number of tables used is limited to a specific number such as 3, the JOIN operations are performed based on the index, and a small amount of data is used. To handle complex queries that do not have these characteristics, the optimizer must meet higher requirements.
PolarDB-X uses a cost-based optimizer that can search for an optimal execution plan based on the volume of the queried data and the data distribution. For example, the optimizer can adjust the order in which the JOIN operations are performed, select an appropriate join or aggregation algorithm, and disassociate associated subqueries. The quality of the execution plan determines the query efficiency. Query optimization is crucial for Analytical Processing (AP) queries.
Read/write splitting
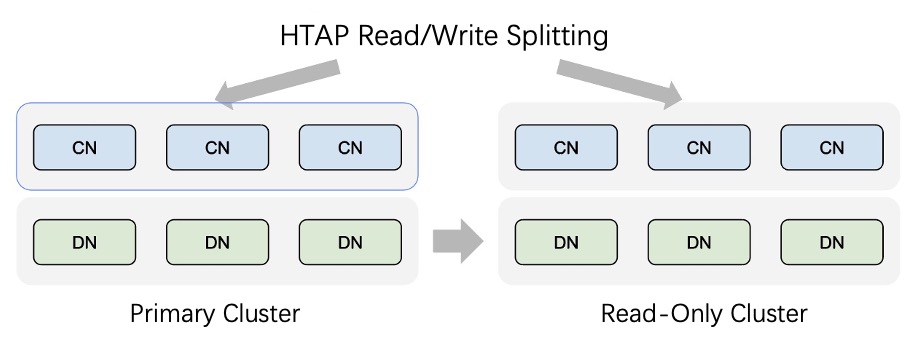
When a large amount of traffic is involved in online business, the PolarDB-X primary instance is under high pressure caused by data reading and writing. In this case, we recommend that you purchase read-only instances for the PolarDB-X primary instance to route a specified portion of TP read queries from the compute nodes of the primary instance to the data nodes of the read-only instances. This way, read queries is split from write queries and the read pressure on the primary instance is reduced.
After you purchase read-only instances for a primary instance for read/write splitting, a read request can be specified as a strong-consistency read request or a weak-consistency read request.
- Strong-consistency read request: After the read request is routed to the read-only instances, the data that is updated on the primary instance before the read requests are performed can be queried. This provides external strong consistency.
- Weak-consistency read request: After the read request is routed to the read-only instances, only the latest data can be read from the read-only instances. Data reads are delayed due to asynchronous replication between your primary and read-only instances.
You can specify the read SQL statements that are executed on the primary instance by configuring hints. You can also specify a proportion of read and write SQL statements executed on the primary instance in advance. For more information, see Cluster endpoints and read-only routing endpoints.
Intelligent read/write splitting
The performance of TP queries is affected by AP queries. This is one of the main issues in the application of HTAP databases. To resolve this issue, we recommend that you deploy a PolarDB-X read-only instance whose hardware is isolated from that of the primary instance. This minimizes the impact of AP queries on TP queries.
The PolarDB-X optimizer classifies requests into TP workloads and AP workloads based on the estimated costs. AP workloads are rewritten as distributed execution plans and sent to read-only instances. This ensures that AP workloads do not affect TP workloads on the primary instance. This way, read and write queries are intelligently split.
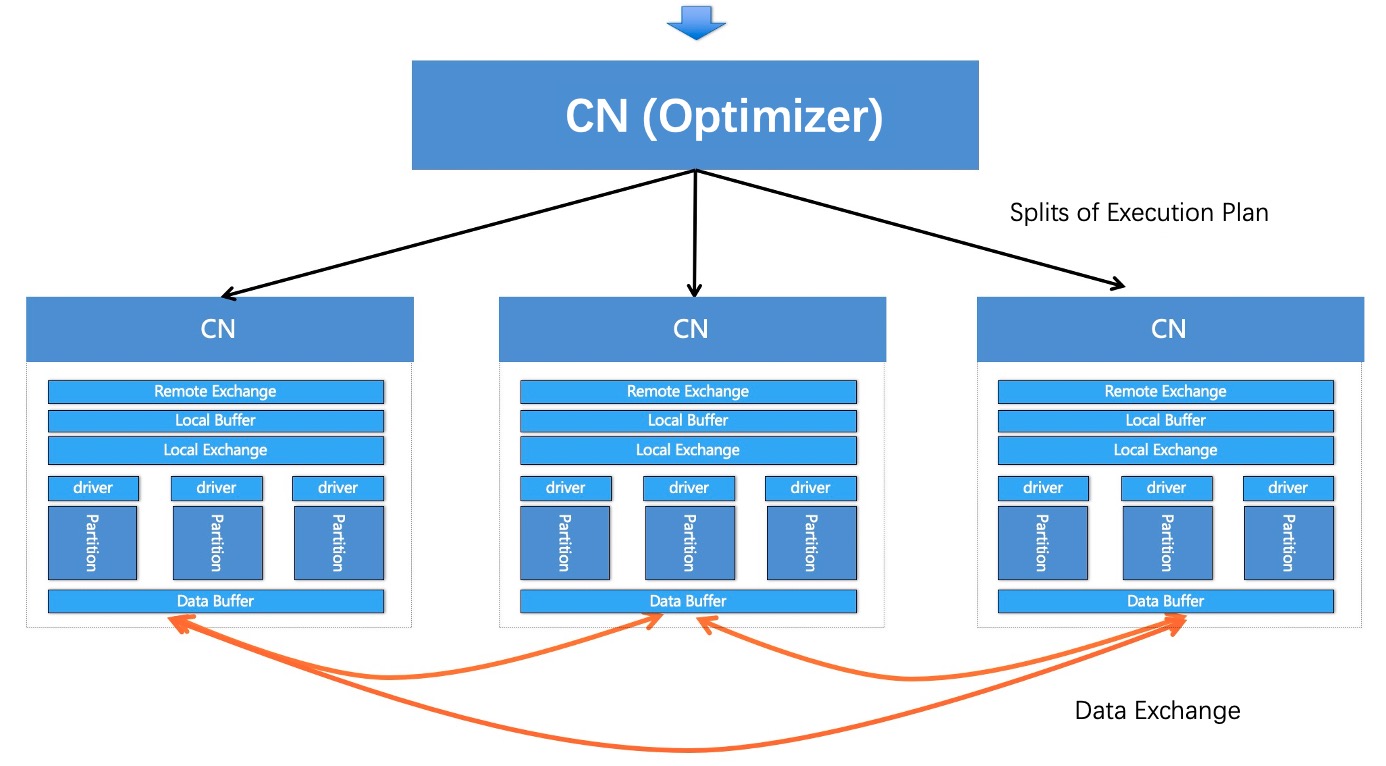
Distributed execution
Each distributed execution plan is divided into multiple stages. The request in each stage is divided into multiple shards. The shards are distributed to multiple compute nodes for execution. Compute nodes are connected by using high-speed networks. In each stage, the calculation result of a subtask is used in other subtasks. In the last stage, the calculation results of all subtasks are collected and sent back to the client that initiates the query.
Globally consistent reads
If the read/write splitting architecture is used, the latency of data replication may cause read-after-write inconsistency. By default, globally consistent reads are supported for the queries routed to PolarDB-X read-only instances. This ensures that the expired data is not read. After data is written to the primary instance, the written data can be read only from the read-only instances.