Distributed linear scalability
Physical distribution of data
PolarDB-X horizontally partitions data tables into multiple data nodes. Data is partitioned based on partitioning functions. PolarDB-X supports common partitioning functions such as hash and range.
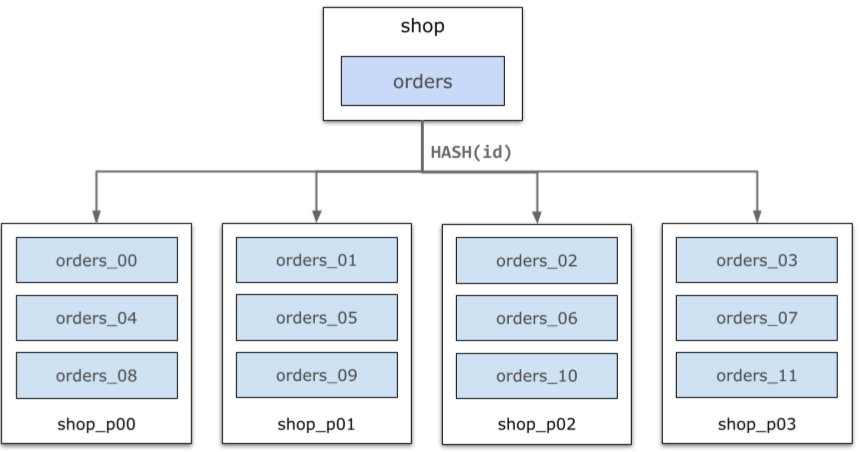
The following figure provides an example. In the example, the orders table in the shop database is horizontally split into 12 partitions from orders_00 through orders_11 based on the hash value of the id column of each row of data. The partitions are distributed on four data nodes in an even manner. The distributed SQL layer of PolarDB-X automatically routes queries and combines result sets.
Scale-out and migration
The amount of data increases when your business grows. In most cases, you need to add data nodes to handle the increasing amount of data. When a new data node is added to a cluster, PolarDB-X automatically triggers a scale-out task to rebalance data.
The following figure provides an example in which the data of the orders table is distributed into four data nodes. After two more data nodes are added to the cluster, a rebalancing task is triggered. PolarDB-X migrates some of the data partitions from the original data nodes to the new data nodes. The migration process is completed in the background by using idle resources and does not affect your online business.
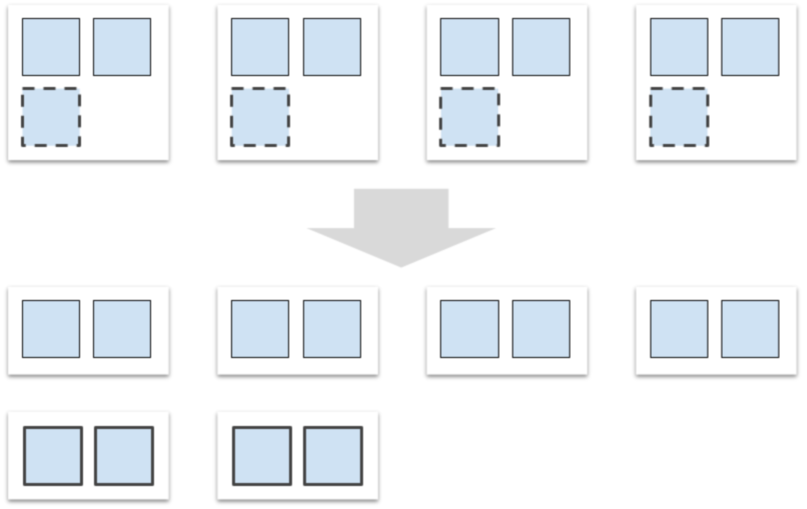
Table groups
To improve the performance of JOIN queries, we recommend that you design the partition key for each PolarDB-X table based on your business scenario. This way, associated tables can be partitioned by using the same method.
For example, in the following figure, the four tables user, orders, lineitem, and delivery use HASH(user_id) as the partitioning function. For higher performance, you can push down the following SQL statements to data nodes for execution:
SELECT * FROM user, orders WHERE user.id = orders.user_id WHERE user.id = ...
PolarDB-X uses table groups to describe tables that use the same partitioning method. In most cases, tables that are partitioned by using the same partitioning function and contain a column of the same data type are automatically classified into the same table group in an implicit manner. Each partition group in the table group contains a partition of each table.
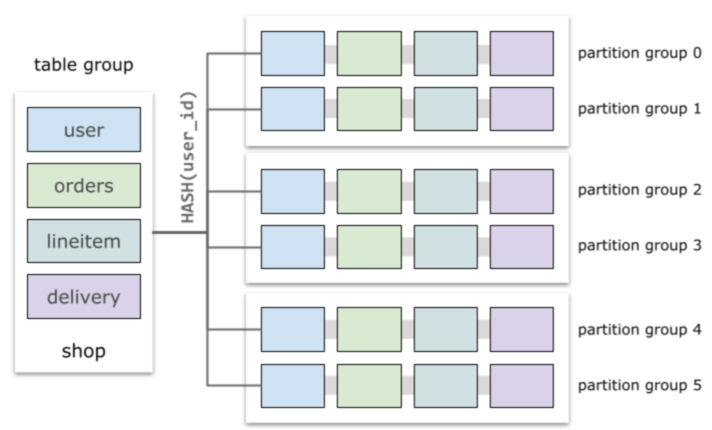
Table groups are important in migrating, splitting, and merging partitions. In the preceding example, if a partition of the user table is migrated but the corresponding partition of the orders table is not migrated, the preceding query cannot be pushed down to the data nodes, which may significantly reduce performance. This issue can be resolved by using table groups. In the preceding example, the user table and the orders table belong to the same table group. If a migration, splitting, or merging operation is performed on a partition of one table, PolarDB-X synchronizes the operation to the corresponding partition of the other table.