备份恢复
本文将介绍如何对PolarDB-X实例进行备份恢复。
测试条件
原实例拓扑如下:
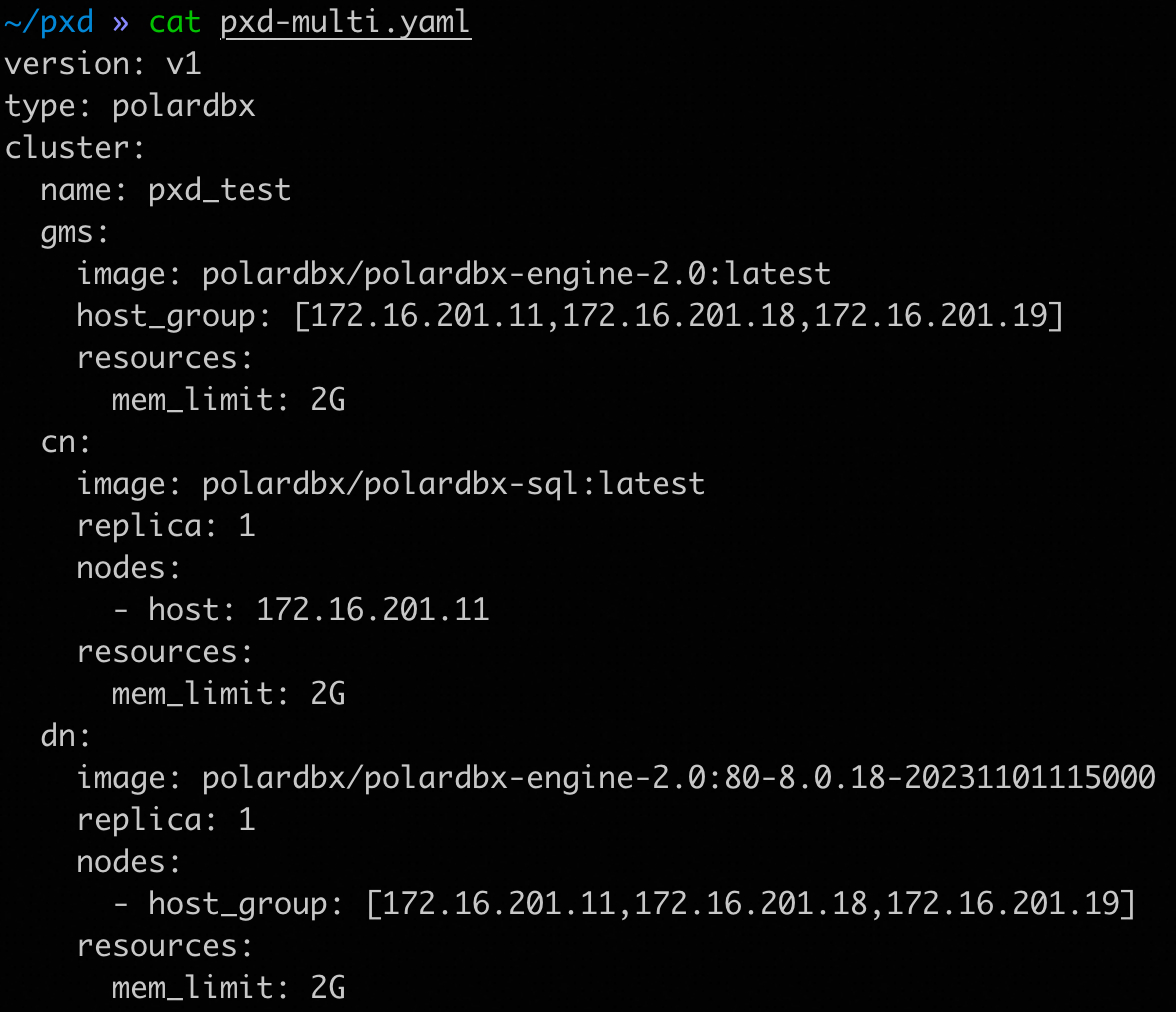 其中DN各节点角色情况如下:
其中DN各节点角色情况如下:
| 节点名 | 角色 | IP | 容器名 |
|---|---|---|---|
| pxd_test-gms | Leader | 172.16.201.11 | pxd_test-gms-Cand-0-15594 |
| pxd_test-gms | Follower | 172.16.201.18 | pxd_test-gms-Cand-1-15566 |
| pxd_test-gms | Logger | 172.16.201.19 | pxd_test-gms-Logger-2-14519 |
| pxd_test-dn-0 | Leader | 172.16.201.11 | pxd_test-dn-0-Cand-0-14321 |
| pxd_test-dn-0 | Follower | 172.16.201.18 | pxd_test-dn-0-Cand-1-17467 |
| pxd_test-dn-0 | Logger | 172.16.201.11 | pxd_test-dn-0-Logger-2-15828 |
登录polardb-x实例,准备一下测试数据,其中TS1是做全量备份时的时间点,TS2是希望恢复到的时间点:
CREATE DATABASE db MODE=AUTO;
USE db;
CREATE TABLE tb (
id bigint auto_increment,
bid varchar(32),
name varchar(32),
primary key(id)
);
# 全量备份之前
INSERT INTO tb(bid, name) values("1", "a");
INSERT INTO tb(bid, name) values("2", "b");
INSERT INTO tb(bid, name) values("3", "c");
INSERT INTO tb(bid, name) values("4", "d");
INSERT INTO tb(bid, name) values("5", "e");
INSERT INTO tb(bid, name) values("6", "f");
INSERT INTO tb(bid, name) values("7", "g");
INSERT INTO tb(bid, name) values("8", "h");
# 此时对各存储节点做全量备份,备份方式见第二节备份数据
SELECT UNIX_TIMESTAMP() AS TS1;
# 恢复时间点前
INSERT INTO tb(bid, name) values("9", "i");
INSERT INTO tb(bid, name) values("10", "j");
INSERT INTO tb(bid, name) values("11", "k");
INSERT INTO tb(bid, name) values("12", "l");
# 恢复时间点
# 期望恢复出id为1~12的数据
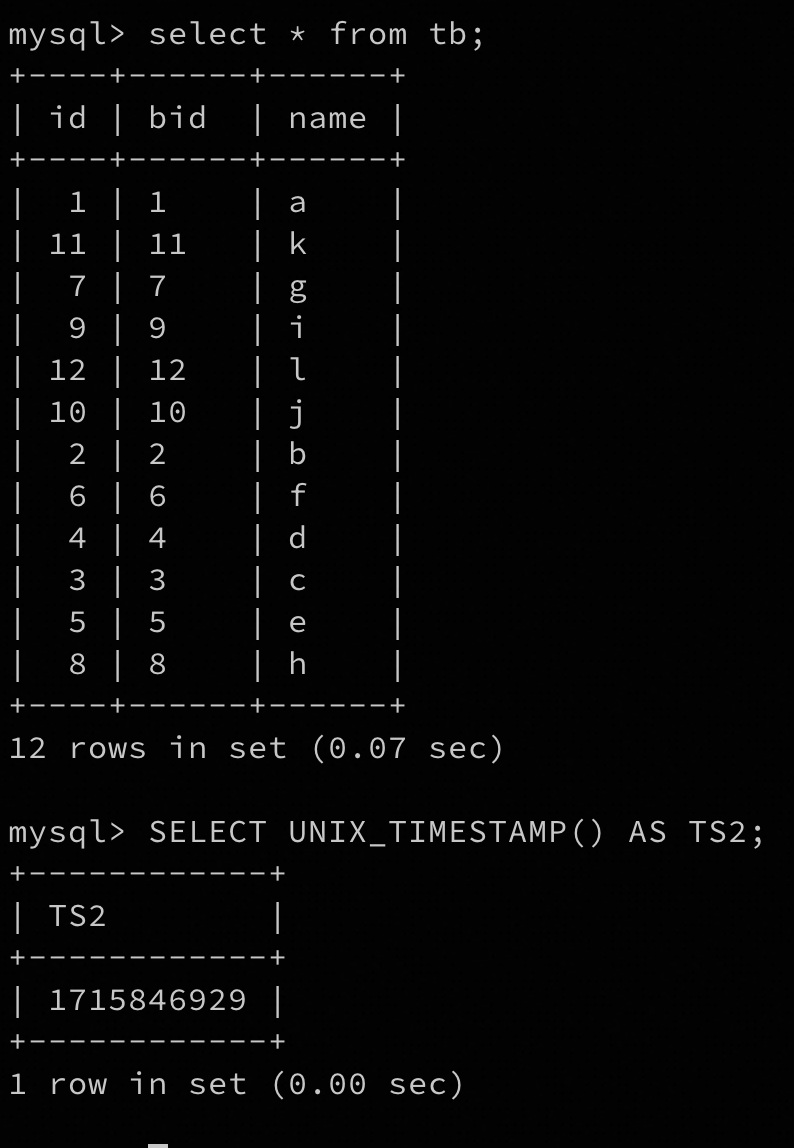
SELECT UNIX_TIMESTAMP() AS TS2;
# 恢复时间点后,会以此时的binlog进行时间点恢复,binlog备份方式见第三节备份binlog
INSERT INTO tb(bid, name) values("13", "m");
INSERT INTO tb(bid, name) values("14", "n");
INSERT INTO tb(bid, name) values("15", "o");
INSERT INTO tb(bid, name) values("16", "p");
这里全量备份的时间戳是1715844883,
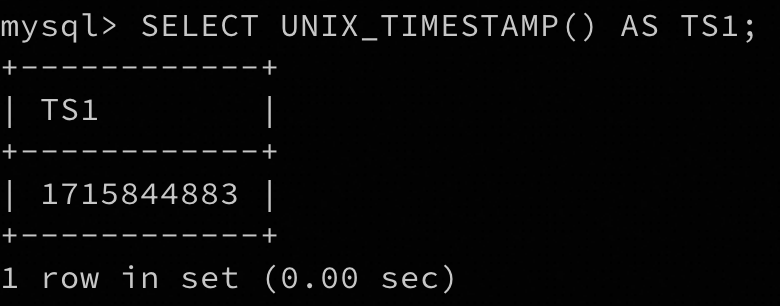 期望恢复到的时间戳是1715846929。
期望恢复到的时间戳是1715846929。
备份数据
在TS1时间对各数据节点进行备份,包括GMS节点:
由于备份时可能会对存储节点性能造成影响,建议在备库执行
备份方式
登录存储节点容器,执行备份命令,将dnContainerName替换成对应容器名,将dnVersion替换成与DN内核对应的大版本(8018/8032):
mkdir -p /home/polardbx/backup/{dnContainerName} && docker exec {dnContainerName} bash -c "/tools/xstore/current/xtrabackup/{dnVersion}/xcluster_xtrabackup80/bin/xtrabackup --stream=xbstream --socket=/data/mysql/run/mysql.sock --slave-info --backup --lock-ddl --xtrabackup-plugin-dir=/tools/xstore/current/xtrabackup/{dnVersion}/xcluster_xtrabackup80/lib/plugin" >/home/polardbx/backup/{dnContainerName}/backup.xbstream 2>/home/polardbx/backup/{dnContainerName}/backup.log
对于测试场景中的实例,登录GMS的follower节点机器172.16.201.18:
mkdir -p /home/polardbx/backup/pxd_test-gms-Cand-1-15566 && docker exec pxd_test-gms-Cand-1-15566 bash -c '/tools/xstore/current/xtrabackup/8018/xcluster_xtrabackup80/bin/xtrabackup --stream=xbstream --socket=/data/mysql/run/mysql.sock --slave-info --backup --lock-ddl --xtrabackup-plugin-dir=/tools/xstore/current/xtrabackup/8018/xcluster_xtrabackup80/lib/plugin' >/home/polardbx/backup/pxd_test-gms-Cand-1-15566/backup.xbstream 2>/home/polardbx/backup/pxd_test-gms-Cand-1-15566/backup.log
登录DN-0的follower节点机器172.16.201.18:
mkdir -p /home/polardbx/backup/pxd_test-dn-0-Cand-1-17467 && docker exec pxd_test-dn-0-Cand-1-17467 bash -c '/tools/xstore/current/xtrabackup/8018/xcluster_xtrabackup80/bin/xtrabackup --stream=xbstream --socket=/data/mysql/run/mysql.sock --slave-info --backup --lock-ddl --xtrabackup-plugin-dir=/tools/xstore/current/xtrabackup/8018/xcluster_xtrabackup80/lib/plugin' >/home/polardbx/backup/pxd_test-dn-0-Cand-1-17467/backup.xbstream 2>/home/polardbx/backup/pxd_test-dn-0-Cand-1-17467/backup.log
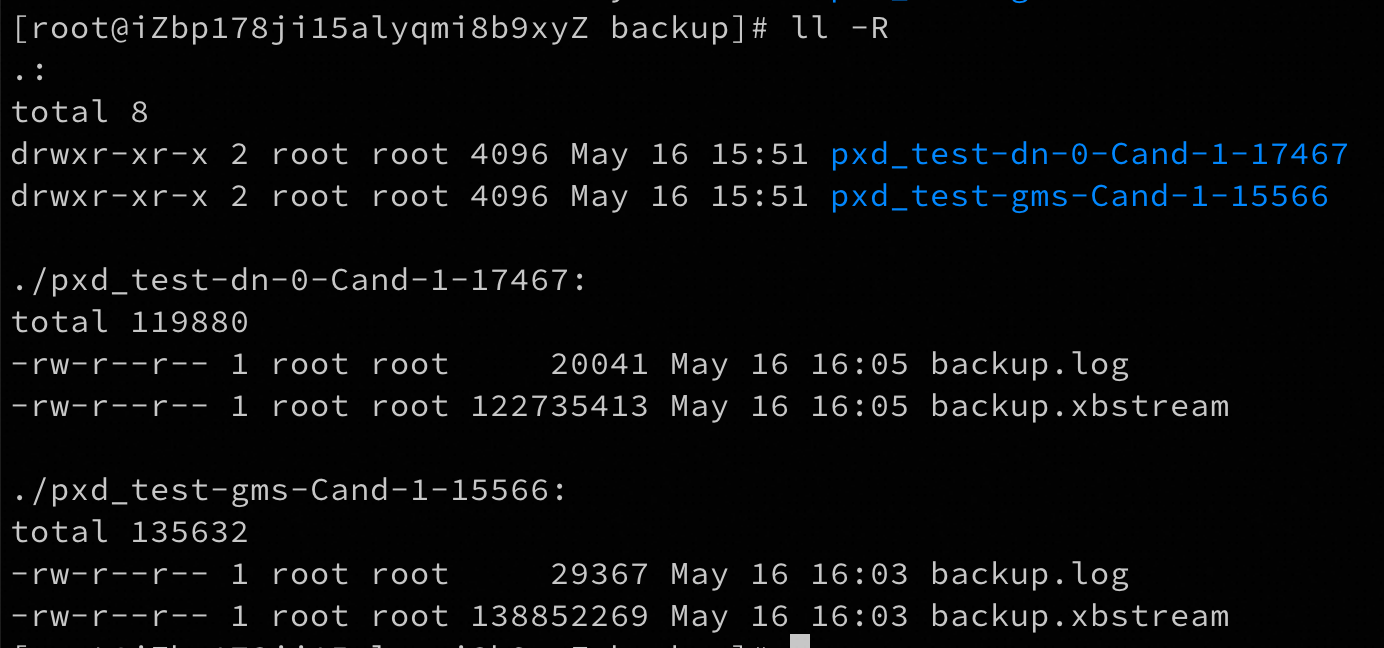
备份后的文件内容如下:
记录原实例信息
登录任一CN节点所在的机器,找到对应的容器:
 执行如下命令,从环境变量中获取dnPasswordKey:
执行如下命令,从环境变量中获取dnPasswordKey:
docker exec {cnContainerName} bash -c 'echo $dnPasswordKey'
记录下dnPasswordKey,在恢复实例时需要使用,在测试场景中dnPasswordKey是JLLptspJycIOmNtI:
 执行如下命令,获取原GMS的密码:
执行如下命令,获取原GMS的密码:
docker exec {cnContainerName} bash -c 'echo $dnPasswordKey'
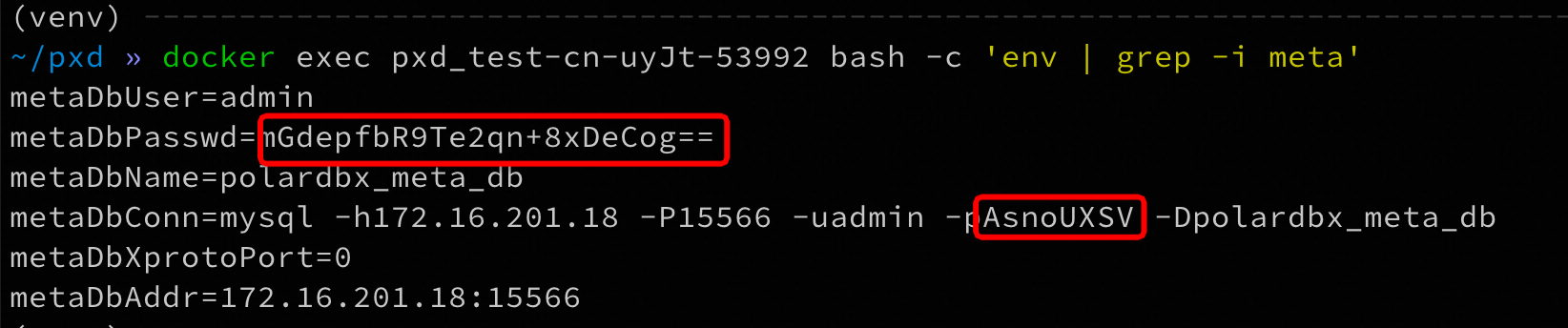 记录下metadbConn中的密码和metaDbPasswd,前者是明文,后者是密文,在测试场景中的密码情况如下:
记录下metadbConn中的密码和metaDbPasswd,前者是明文,后者是密文,在测试场景中的密码情况如下:
- 明文:AsnoUXSV
- 密文:mGdepfbR9Te2qn+8xDeCog==
备份Binlog
这一节介绍如何备份各数据节点的binlog,以恢复到TS2时的数据:备份方式
需要登录到数据节点的机器上(包括GMS和DN),执行下列binlog备份脚本,需要传入三个参数,source_dn_container_name是存储节点容器名,full_backup_timestamp是全量备份的时间戳,restore_timestamp是恢复时间点的时间戳。
#!/bin/bash
source_dn_container_name=$1
full_backup_timestamp=$2
restore_timestamp=$3
readarray -t binlog_list < <(docker exec ${source_dn_container_name} bash -c "cd /data/mysql/log/ && ls -1 | grep mysql_bin.0 | xargs -I{} stat -c '%Y %n' {}" | awk -v ts="$full_backup_timestamp" '$1 > ts {print $2}')
binlog_list_length=${#binlog_list[@]}
copy_list=()
for i in $(seq $((binlog_list_length - 1)) -1 0); do
echo "deal with ${binlog_list[$i]}"
docker exec ${source_dn_container_name} bash -c "cp /data/mysql/log/${binlog_list[$i]} /tmp/${binlog_list[$i]}"
original_md5=$(docker exec ${source_dn_container_name} bash -c "md5sum /tmp/${binlog_list[$i]}")
docker exec ${source_dn_container_name} bash -c "/tools/xstore/current/bb truncate --end-ts=${restore_timestamp} --output=/tmp/tmp_binlog /tmp/${binlog_list[$i]}"
truncated_md5=$(docker exec ${source_dn_container_name} bash -c "md5sum /tmp/tmp_binlog")
docker exec ${source_dn_container_name} bash -c "rm /tmp/${binlog_list[$i]}"
if [ "$original_md5" = "$truncated_md5" ]; then
echo "md5 has not changed after truncate, no need to copy this binlog"
else
copy_list+=("${binlog_list[$i]}")
fi
done
for binlog in "${binlog_list[@]}"; do
echo "copy $binlog"
docker cp $source_dn_container_name:/data/mysql/log/$binlog /home/polardbx/backup/$source_dn_container_name
done
bash binlog_backup.sh {sourceDNContainer} {fullBackupTimestamp} {restoreTimestamp}
对于测试场景中的GMS,执行如下命令:
bash binlog_backup.sh pxd_test-gms-Cand-1-15566 1715844883 1715846929
对于DN,执行如下命令:
bash binlog_backup.sh pxd_test-dn-0-Cand-1-17467 1715844883 1715846929
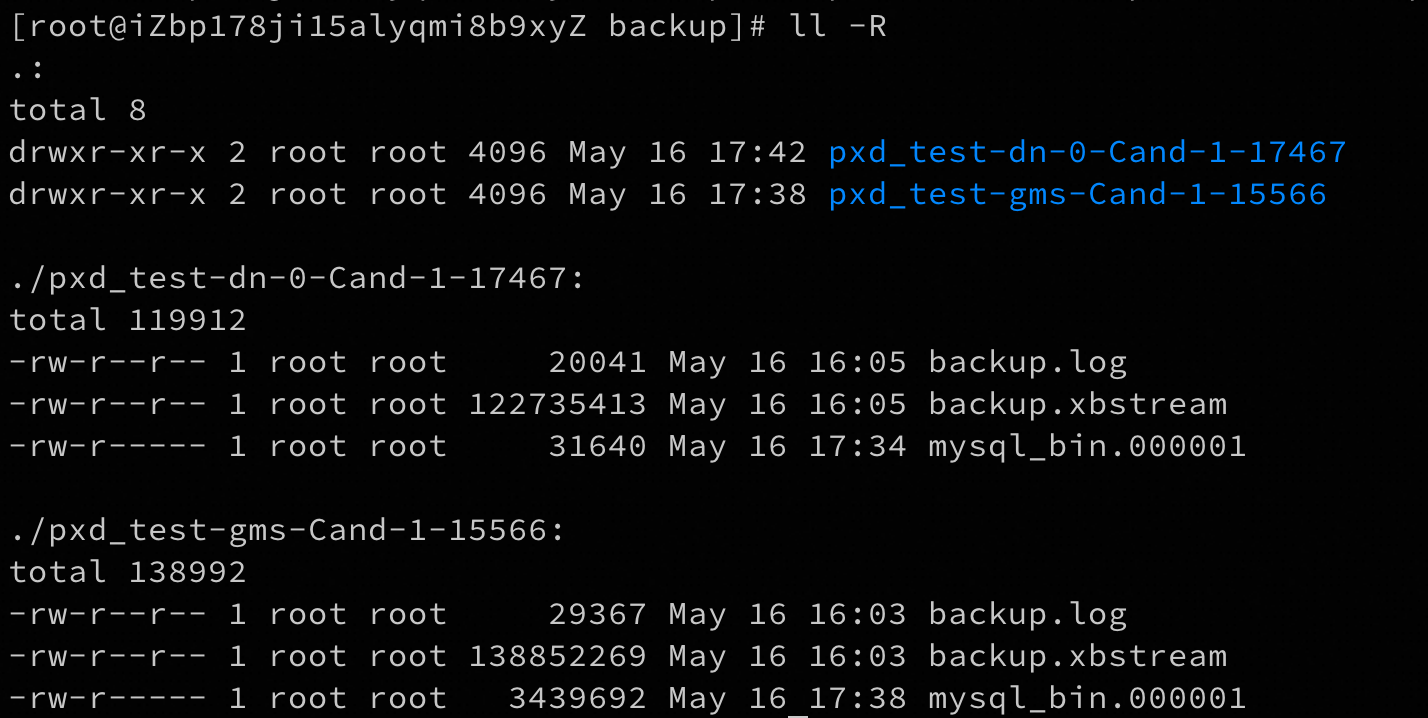
备份的文件内容如下:
新建实例
创建新实例
新建实例拓扑如下,创建实例时注意传入备份数据时保存的dnPasswordKey:
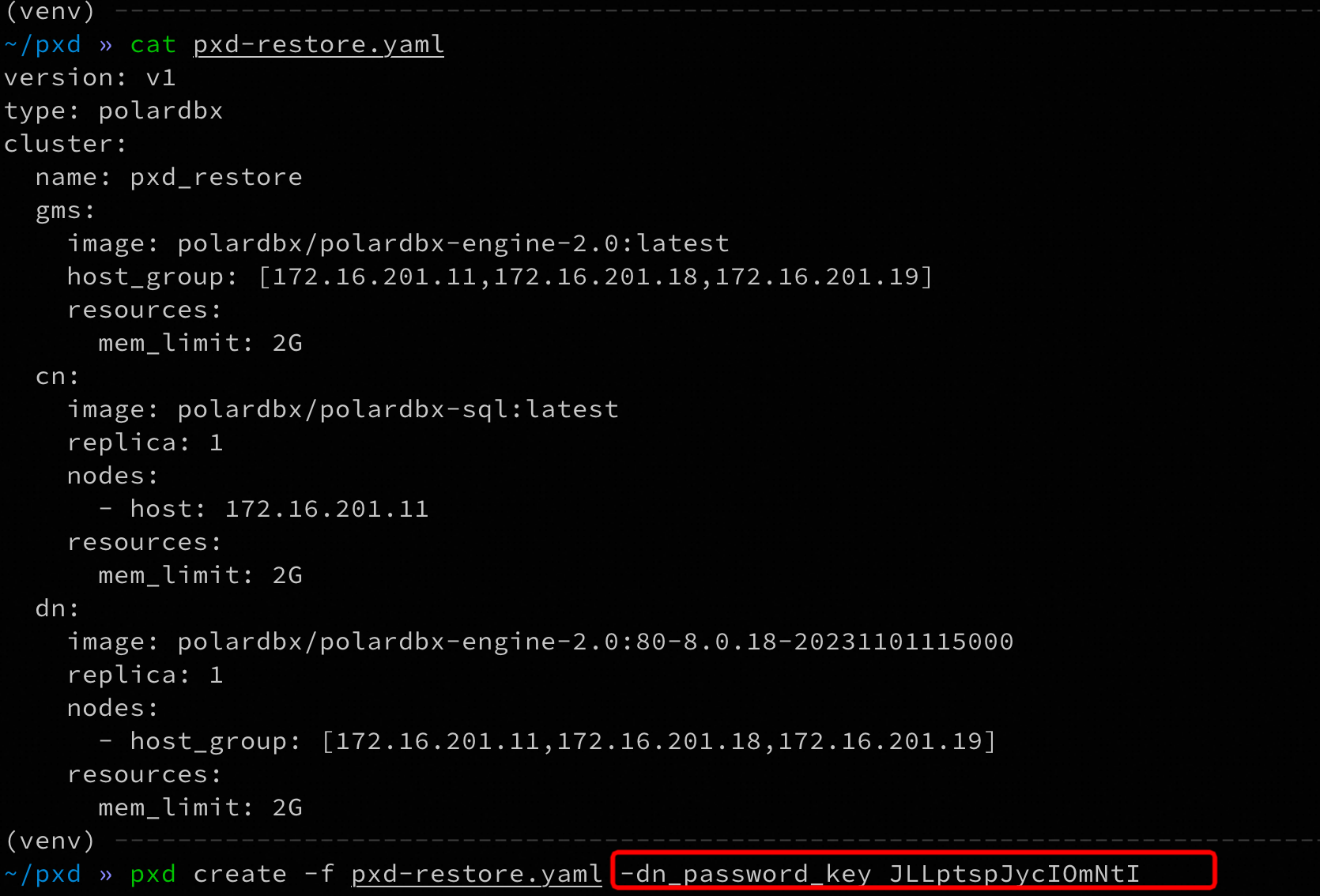
pxd create -f pxd-restore.yaml -dn_password_key {dnPasswordKey}
其中DN各节点角色情况如下,由于是恢复实例,还要建立起和原实例DN的映射关系,其中的标红的节点需要执行后续的数据恢复步骤:
| 节点名 | 角色 | IP | 容器名 | 原实例容器名(执行备份的容器名) |
|---|---|---|---|---|
| pxd_restore-gms | Leader | 172.16.201.11 | pxd_restore-gms-Cand-0-15295 | pxd_test-gms-Cand-1-15566 |
| pxd_restore-gms | Follower | 172.16.201.18 | pxd_restore-gms-Cand-1-15255 | pxd_test-gms-Cand-1-15566 |
| pxd_restore-gms | Logger | 172.16.201.19 | pxd_restore-gms-Logger-2-17057 | pxd_test-gms-Cand-1-15566 |
| pxd_restore-dn-0 | Leader | 172.16.201.11 | pxd_restore-dn-0-Cand-0-17713 | pxd_test-dn-0-Cand-1-17467 |
| pxd_restore-dn-0 | Follower | 172.16.201.18 | pxd_restore-dn-0-Cand-1-16647 | pxd_test-dn-0-Cand-1-17467 |
| pxd_restore-dn-0 | Logger | 172.16.201.11 | pxd_restore-dn-0-Logger-2-17466 | pxd_test-dn-0-Cand-1-17467 |
恢复数据节点(包括GMS)
数据节点包括Leader、Follower和Logger三种角色,对于前两种角色需要进行数据恢复。
停止Logger进程
在恢复Leader和Follower的数据之前,需要执行如下命令将Logger进程先停止:
docker exec {loggerContainerName} bash -c "touch /data/mysql/disable_engine"
docker restart {loggerContainerName}
对于测试场景中的GMS,登上对应机器,执行:
docker exec pxd_restore-gms-Logger-2-17057 bash -c "touch /data/mysql/disable_engine"
docker restart pxd_restore-gms-Logger-2-17057
检查发现mysqld进程已退出:
 对于DN,登上对应机器,执行:
对于DN,登上对应机器,执行:
docker exec pxd_restore-dn-0-Logger-2-17466 bash -c "touch /data/mysql/disable_engine"
docker restart pxd_restore-dn-0-Logger-2-17466
检查发现mysqld进程已退出:

恢复Leader、Follower数据
对于Leader和Follower需要恢复数据,登录到新建DN容器的机器上,执行以下脚本,需要提供以下参数
dest_dn_container_name:需要恢复数据的新建DN容器source_dn_container_name:执行备份的DN容器backup_path:备份文件保存的路径last_binlog_name:最后一个binlog名,即备份路径中mysql_bin中index最大的那个end_ts:需要恢复到的时间戳dn_version:dn内核大版本,可填8018或8032,与备份数据时填入的保持一致需自行将备份文件拷贝至待恢复的机器上
#!/bin/bash
dest_dn_container_name=$1
source_dn_container_name=$2
backup_path=$3
last_binlog_name=$4
end_ts=$5
dn_version=$6
clear_directory() {
echo "clear data and log directory"
docker exec $dest_dn_container_name bash -c "touch /data/mysql/disable_engine"
docker restart $dest_dn_container_name
docker exec $dest_dn_container_name bash -c "rm -rf /data/mysql/data/*"
docker exec $dest_dn_container_name bash -c "rm -rf /data/mysql/log/*"
docker exec $dest_dn_container_name bash -c "rm -rf /data/mysql/backup"
}
prepare_backup_data() {
echo "copy backup data"
docker cp $backup_path $dest_dn_container_name:/data/mysql/backup
echo "decompress backup data"
docker exec $dest_dn_container_name bash -c "/tools/xstore/current/xtrabackup/$dn_version/xcluster_xtrabackup80/bin/xbstream -x < /data/mysql/backup/backup.xbstream -C /data/mysql/data"
docker exec $dest_dn_container_name bash -c "/tools/xstore/current/xtrabackup/$dn_version/xcluster_xtrabackup80/bin/xtrabackup --defaults-file=/data/mysql/conf/my.cnf --prepare --target-dir=/data/mysql/data --xtrabackup-plugin-dir=/tools/xstore/current/xtrabackup/$dn_version/xcluster_xtrabackup80/lib/plugin 2> /data/mysql/log/applybackup.log"
docker exec $dest_dn_container_name bash -c "mv /data/mysql/data/undo_* /data/mysql/log"
docker exec $dest_dn_container_name bash -c "chown -R mysql:mysql /data/mysql/data/*"
fileList=()
original_ifs="$IFS"
while IFS= read -r -d '' file; do
fileName=$(basename "$file")
fileList+=("$fileName")
done < <(find "$backup_path" -type f -name "my*" -print0)
echo "copy binlog"
for file in "${fileList[@]}"; do
echo "copy $file"
docker exec $dest_dn_container_name bash -c "cp /data/mysql/backup/$file /data/mysql/log/"
docker exec $dest_dn_container_name bash -c "echo '/data/mysql/log/$file' >> /data/mysql/log/mysql_bin.index"
done
echo "truncate the last binlog"
docker exec $dest_dn_container_name bash -c "/tools/xstore/current/bb truncate /data/mysql/log/$last_binlog_name --end-ts $end_ts -o /data/mysql/log/$last_binlog_name.new"
docker exec $dest_dn_container_name bash -c " mv /data/mysql/log/$last_binlog_name /data/mysql/log/$last_binlog_name.bak"
docker exec $dest_dn_container_name bash -c " mv /data/mysql/log/$last_binlog_name.new /data/mysql/log/$last_binlog_name"
docker exec $dest_dn_container_name bash -c "chown -R mysql:mysql /data/mysql/log/*"
}
apply_backup_data() {
echo "apply backup data"
xtrabackup_binlog_info=$(docker exec $dest_dn_container_name bash -c "cat /data/mysql/data/xtrabackup_binlog_info")
start_index=$(echo "$xtrabackup_binlog_info" | awk '{print $2}')
echo $start_index
last_binlog_info=$(docker exec $dest_dn_container_name bash -c "/tools/xstore/current/xtrabackup/$dn_version/xcluster_xtrabackup80/bin/mysqlbinlogtailor --show-index-info /data/mysql/log/$last_binlog_name")
IFS=':, '
read -r -a index_term_list <<< "${last_binlog_info//[\[\]]/}"
end_term=${index_term_list[3]}
echo $end_term
shared_channel_json=$(docker exec $dest_dn_container_name bash -c "cat /data/shared/shared-channel.json")
echo $shared_channel_json
IFS="$original_ifs"
pod_name=$(docker exec $dest_dn_container_name bash -c 'echo $POD_NAME')
echo $pod_name
ip_port=$(echo $shared_channel_json | jq --arg pod_name "$pod_name" -r '.nodes[] | select(.pod == $pod_name) | "\(.host):\(.port)"')
echo $ip_port
init_command="/opt/galaxy_engine/bin/mysqld --defaults-file=/data/mysql/conf/my.cnf --cluster-info=$ip_port@1 --cluster-force-change-meta=ON --loose-cluster-force-recover-index=$start_index --cluster-start-index=$start_index --cluster-current-term=$end_term --cluster-force-single-mode=ON"
echo $init_command
docker exec $dest_dn_container_name bash -c "$init_command"
docker exec $dest_dn_container_name bash -c "/opt/galaxy_engine/bin/mysqld --defaults-file=/data/mysql/conf/my.cnf --user=mysql &"
}
clear_directory
prepare_backup_data
apply_backup_data
bash restore.sh {destDnContainerName} {sourceDnContainerName} {backupPath} {lastBinlogName} {endTs}
对于测试场景中的GMS的Leader节点,执行如下命令:
bash restore.sh pxd_restore-gms-Cand-0-15295 pxd_test-gms-Cand-1-15566 /home/polardbx/backup/pxd_test-gms-Cand-1-15566 mysql_bin.000001 1715846929 8018
Follower节点:
bash restore.sh pxd_restore-gms-Cand-1-15255 pxd_test-gms-Cand-1-15566 /home/polardbx/backup/pxd_test-gms-Cand-1-15566 mysql_bin.000001 1715846929 8018
对于测试场景中DN的Leader节点,执行如下命令:
bash restore.sh pxd_restore-dn-0-Cand-0-17713 pxd_test-dn-0-Cand-1-17467 /home/polardbx/backup/pxd_test-dn-0-Cand-1-17467 mysql_bin.000001 1715846929 8018
Follower节点:
bash restore.sh pxd_restore-dn-0-Cand-1-16647 pxd_test-dn-0-Cand-1-17467 /home/polardbx/backup/pxd_test-dn-0-Cand-1-17467 mysql_bin.000001 1715846929 8018
恢复过程会伴随一些日志输出,可以检查下容器中mysqld进程是否已经拉起,拉起说明处于恢复中:
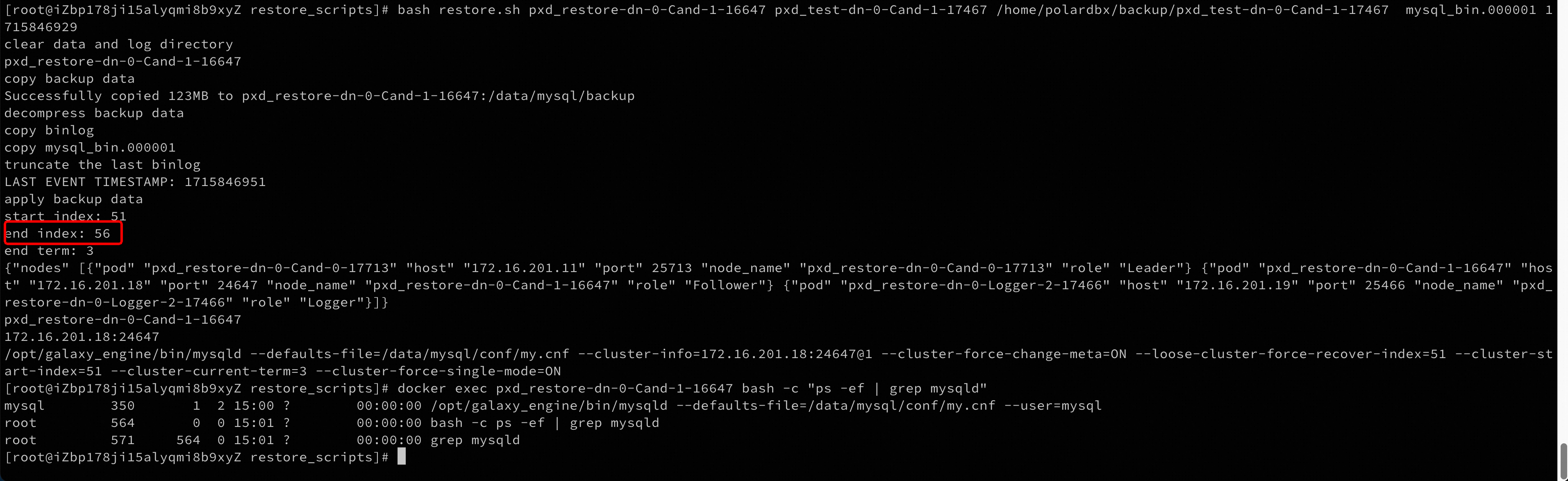 注意记录一下日志输出中的
注意记录一下日志输出中的end_index,它代表着恢复结束的位点。
重启Leader、Follower进程
启动mysqld进程后,需要等待数据恢复完成,可以按以下方式检查恢复进度,首先执行下列命令登录恢复出的节点的数据库:
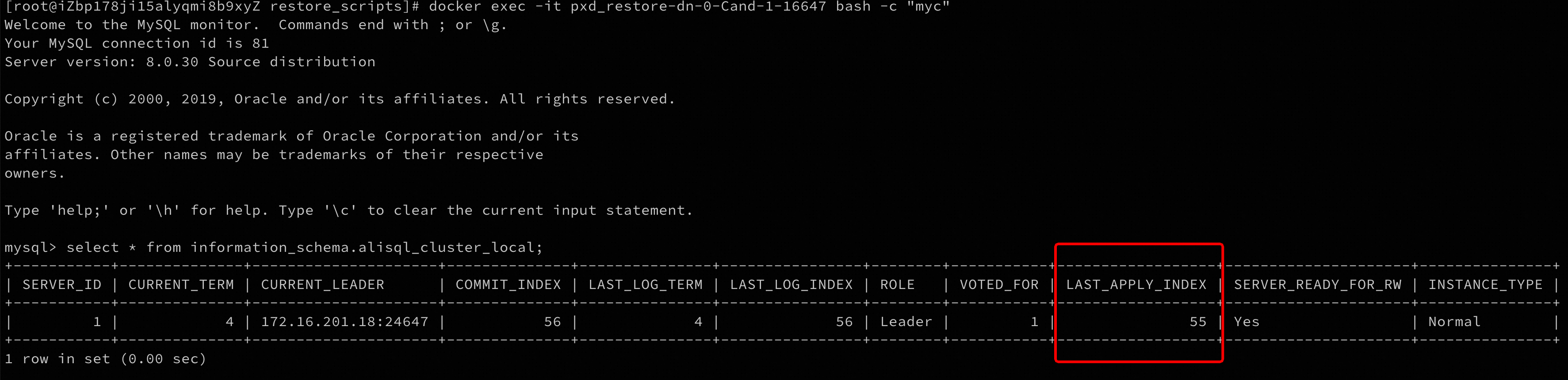
docker exec -it {destDnContainerName} bash -c "myc"
然后执行该SQL检查恢复进度:
select * from information_schema.alisql_cluster_local;
如果发现LAST_APPLY_INDEX已经等于了上面输出的end_index,则可以重新将该节点组装进集群中以提供服务。
 对于恢复完成的节点(Leader/Follower),可以运行下列脚本,重新组装进集群,需要提供一个参数
对于恢复完成的节点(Leader/Follower),可以运行下列脚本,重新组装进集群,需要提供一个参数dest_dn_container_name,即节点对应的容器名:
dest_dn_container_name=$1
docker restart $dest_dn_container_name
shared_channel_json=$(docker exec $dest_dn_container_name bash -c "cat /data/shared/shared-channel.json")
echo $shared_channel_json
pod_name=$(docker exec $dest_dn_container_name bash -c 'echo $POD_NAME')
echo $pod_name
ip_port_list=$(echo $shared_channel_json | jq -r '[.nodes[] | "\(.host):\(.port)"] | join(";")')
index=$(echo $shared_channel_json | jq --arg pod_name "$pod_name" -r '.nodes | to_entries | .[] | select(.value.pod == $pod_name) | (.key + 1)')
init_command="/opt/galaxy_engine/bin/mysqld --defaults-file=/data/mysql/conf/my.cnf --cluster-info='$ip_port_list@$index' --cluster-force-change-meta=ON"
echo $init_command
docker exec $dest_dn_container_name bash -c "$init_command"
docker exec $dest_dn_container_name bash -c "rm /data/mysql/disable_engine"
docker restart $dest_dn_container_name
对于测试场景中的GMS的Leader节点,执行如下命令:
bash restart.sh pxd_restore-gms-Cand-0-15295
Follower节点:
bash restart.sh pxd_restore-gms-Cand-1-15255
对于测试场景中DN的Leader节点,执行如下命令:
bash restart.sh pxd_restore-dn-0-Cand-0-17713
Follower节点:
bash restart.sh pxd_restore-dn-0-Cand-1-16647
重启过程会有些日志输出,可以检查下mysqld进程是否已经拉起:

重启Logger进程
待一个DN的Leader和Follower都已经恢复并重启完成后,就可以把Logger节点重新拉起:
docker exec {loggerContainerName} bash -c " /data/mysql/disable_engine"
docker restart {loggerContainerName}
对于测试场景中的GMS,登上对应机器,执行:
docker exec pxd_restore-gms-Logger-2-17057 bash -c "rm /data/mysql/disable_engine"
docker restart pxd_restore-gms-Logger-2-17057
检查发现mysqld进程已拉起: 对于DN,登上对应机器,执行
对于DN,登上对应机器,执行
docker exec pxd_restore-dn-0-Logger-2-17466 bash -c "rm /data/mysql/disable_engine"
docker restart pxd_restore-dn-0-Logger-2-17466
检查发现mysqld进程已拉起:

修正gms leader身份
pxd部署期望host_group中第一个节点为leader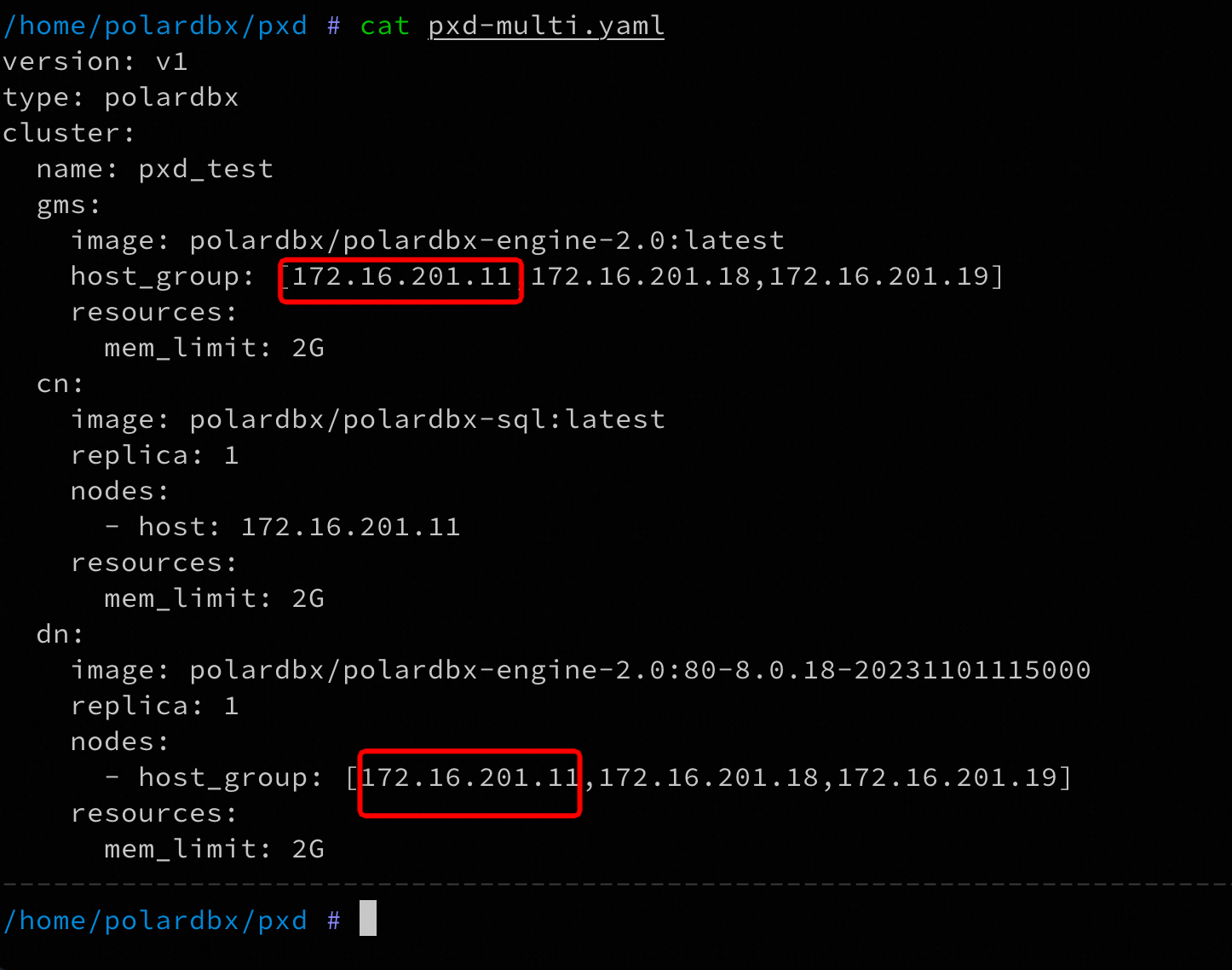 登录GMS leader节点的容器pxd_restore-gms-Cand-0-15295,执行
登录GMS leader节点的容器pxd_restore-gms-Cand-0-15295,执行myc连上数据库,可以执行下列SQL确认当前是否为leader:
select * from information_schema.alisql_cluster_local;
 发现此时当前节点不为leader,我们登录current_leader指向的机器,登录对应的容器,这里就是pxd_restore-gms-Cand-1-15255,执行
发现此时当前节点不为leader,我们登录current_leader指向的机器,登录对应的容器,这里就是pxd_restore-gms-Cand-1-15255,执行myc连上数据库,执行以下SQL查询集群情况,
select * from information_schema.alisql_cluster_global;
 执行以下SQL转让leader:
执行以下SQL转让leader:
# 需要将{expectedIpPort}替换成期望的节点
call dbms_consensus.change_leader("{expectedIpPort}");
# 示例:
call dbms_consensus.change_leader("172.16.201.11:23295");
再回到pxd_restore-gms-Cand-0-15295,发现角色变为了Leader。

重建GMS数据
恢复的最后一步是登录GMS的Leader节点,对polardb-x元数据进行更新,这里即登录pxd_restore-gms-Cand-0-15295,使用polardbx_meta_db数据库,开始重建元数据:
use polardbx_meta_db;
更新db_info:
# 需要将{dstPxdName}替换为新实例名
update ignore db_info set app_name = concat(db_name,concat('@','{dstPxdName}'));
# 示例
update ignore db_info set app_name = concat(db_name,concat('@','pxd_restore'));
更新group_detail_info:
# 需要将{srcPxdName}, {dstPxdName}, {srcGmsName}, {dstGmsName}, {srcDnName}, {dstDnName}替换
# 若有多个DN,需要注意{srcDnName}与{dstDnName}的对应关系,用哪个{srcDnName}的备份集恢复的,就更新为对应的{dstDnName}
update ignore group_detail_info set inst_id = '{dstPxdName}' where inst_id = '{srcPxdName}';
update ignore group_detail_info set storage_inst_id= '{dstGmsName}' where storage_inst_id= '{srcGmsName}';
update ignore group_detail_info set storage_inst_id= '{dstDnName}' where storage_inst_id= '{srcDnName}';
# 示例:
update ignore group_detail_info set inst_id = 'pxd_restore' where inst_id = 'pxd_test';
update ignore group_detail_info set storage_inst_id= 'pxd_restore-gms' where storage_inst_id= 'pxd_test-gms';
update ignore group_detail_info set storage_inst_id= 'pxd_restore-dn-0' where storage_inst_id= 'pxd_test-dn-0';
更新inst_config:
# 需要将{srcPxdName}, {dstPxdName},{dstDnName}替换
# 对于SINGLE_GROUP_STORAGE_INST_LIST,若有多个DN,这里只需填与param_val对应的DN,对应关系参照上述更新group_detail_info时的介绍
update ignore inst_config set param_val = '{dstDnName}' where param_key = 'SINGLE_GROUP_STORAGE_INST_LIST' and inst_id = '{srcPxdName}' limit 1;
update ignore inst_config set inst_id = '{dstDnName}' where inst_id = '{srcDnName}';
# 示例
update ignore inst_config set param_val = 'pxd_restore-dn-0' where param_key = 'SINGLE_GROUP_STORAGE_INST_LIST' and inst_id = 'pxd_test' limit 1;
update ignore inst_config set inst_id = 'pxd_restore' where inst_id = 'pxd_test';
更新config_listener:
# 需要将{srcPxdName}替换
delete from config_listener where data_id like '%.{srcPxdName}.%';
# 示例
delete from config_listener where data_id like '%.pxd_test.%';
清空node_info:
delete from node_info;
更新server_info,这一步需要将新建实例CN的信息进行更新,可以找到CN节点对应的容器,执行以下命令获取各个端口:
docker exe {cnContainerName} bash -c "env | grep -i port"
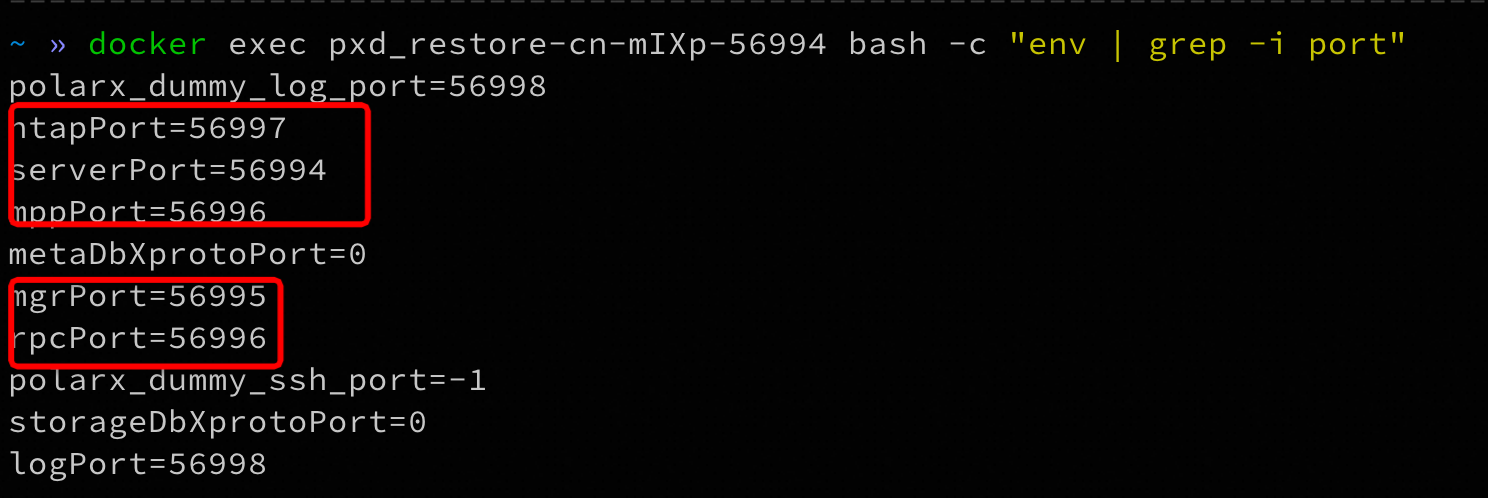
# 需要将{dstPxdName}, {cnIp}, {serverPort}, {htapPort}, {mgrPort},{mppPort}进行替换
delete from server_info;
insert into server_info (id, gmt_created, gmt_modified, inst_id, inst_type, ip, port, htap_port, mgr_port, mpp_port, status, cpu_core, mem_size, extras) values (null, now(), now(), '{dstPxdName}', 0, '{cnIp}', {serverPort}, {htapPort}, {mgrPort}, {mppPort}, 0, 2, 2147483648, null);
# 示例
delete from server_info;
insert into server_info (id, gmt_created, gmt_modified, inst_id, inst_type, ip, port, htap_port, mgr_port, mpp_port, status, cpu_core, mem_size, extras) values (null, now(), now(), 'pxd_restore', 0, '172.16.201.11', 56994, 56997, 56995, 56996, 0, 2, 2147483648, null);
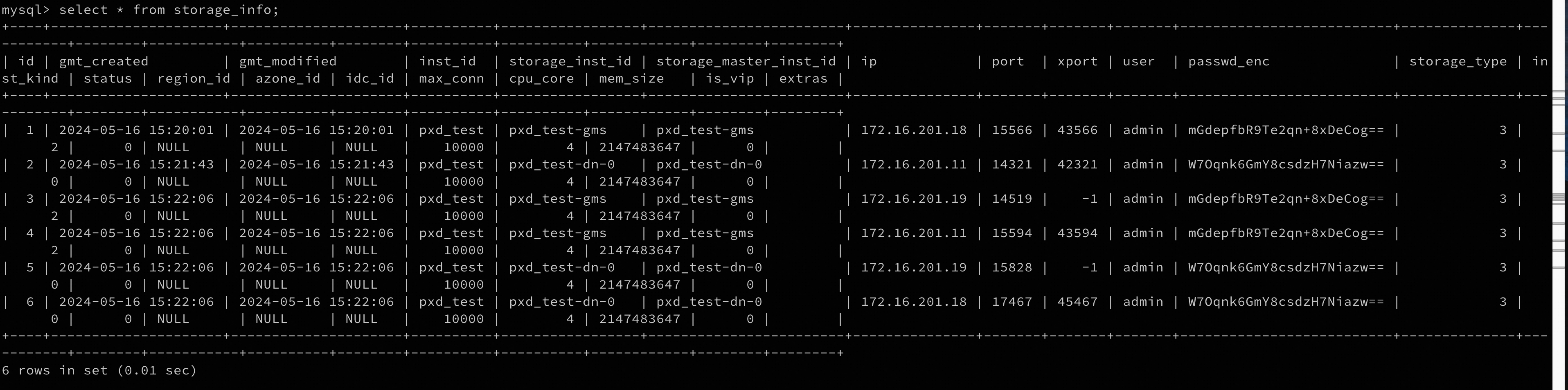
更新storage_info,即存储节点信息,该步较为繁琐,首先执行以下SQL获取原先的存储节点信息:
select * from storage_info;
执行结果如下,我们只需将原DN的如下信息更新成新DN的:inst_id、storage_inst_id、storage_master_inst_id、ip、port、xport
 对于新建的每个存储节点,可以从任一容器获得相关信息:
对于新建的每个存储节点,可以从任一容器获得相关信息:
dokcer exec {dstDnName} bash -c "cat /data/shared/shared-channel.json"
比如对于GMS pxd_restore-gms,可以从pxd_restore-gms-Cand-0-15295中获取信息:
 需要关注
需要关注pod、host两个字段:
pod的数字后缀赌赢storage_info表中的的port,port+28000即为表中的xport(Logger节点无需计算xport)host即为表中的ip
由于更新SQL较为繁琐,我们可以将其余信息从原表中提取出来,生成如下插入SQL:
delete from storage_info;
# gms
insert into storage_info (inst_id, storage_inst_id, storage_master_inst_id, ip, port, xport, user, passwd_enc, storage_type, inst_kind, status, max_conn, cpu_core, mem_size, is_vip) values ('pxd_restore', 'pxd_restore-gms', 'pxd_restore-gms', '172.16.201.11', 15295, 43295, 'admin', 'mGdepfbR9Te2qn+8xDeCog==', 3, 2, 0, 10000, 4, 2147483647, 0);
insert into storage_info (inst_id, storage_inst_id, storage_master_inst_id, ip, port, xport, user, passwd_enc, storage_type, inst_kind, status, max_conn, cpu_core, mem_size, is_vip) values ('pxd_restore', 'pxd_restore-gms', 'pxd_restore-gms', '172.16.201.18', 15255, 43255, 'admin', 'mGdepfbR9Te2qn+8xDeCog==', 3, 2, 0, 10000, 2, 2147483647, 0);
insert into storage_info (inst_id, storage_inst_id, storage_master_inst_id, ip, port, xport, user, passwd_enc, storage_type, inst_kind, status, max_conn, cpu_core, mem_size, is_vip) values ('pxd_restore', 'pxd_restore-gms', 'pxd_restore-gms', '172.16.201.19', 17057, -1, 'admin', 'mGdepfbR9Te2qn+8xDeCog==', 3, 2, 0, 10000, 2, 2147483647, 0);
# dn-0
insert into storage_info (inst_id, storage_inst_id, storage_master_inst_id, ip, port, xport, user, passwd_enc, storage_type, inst_kind, status, max_conn, cpu_core, mem_size, is_vip) values ('pxd_restore', 'pxd_restore-dn-0', 'pxd_restore-dn-0', '172.16.201.11', 17713, 45713, 'admin', 'W7Oqnk6GmY8csdzH7Niazw==', 3, 0, 0, 10000, 4, 2147483647, 0);
insert into storage_info (inst_id, storage_inst_id, storage_master_inst_id, ip, port, xport, user, passwd_enc, storage_type, inst_kind, status, max_conn, cpu_core, mem_size, is_vip) values ('pxd_restore', 'pxd_restore-dn-0', 'pxd_restore-dn-0', '172.16.201.18', 16647, 44647, 'admin', 'W7Oqnk6GmY8csdzH7Niazw==', 3, 0, 0, 10000, 2, 2147483647, 0);
insert into storage_info (inst_id, storage_inst_id, storage_master_inst_id, ip, port, xport, user, passwd_enc, storage_type, inst_kind, status, max_conn, cpu_core, mem_size, is_vip) values ('pxd_restore', 'pxd_restore-dn-0', 'pxd_restore-dn-0', '172.16.201.19', 17466, -1, 'admin', 'W7Oqnk6GmY8csdzH7Niazw==', 3, 0, 0, 10000, 2, 2147483647, 0);
配置quaratine_config:
delete from quarantine_config;
insert into quarantine_config (gmt_created, gmt_modified, inst_id, group_name, net_work_type, security_ip_type, security_ips) values (now(), now(), "pxd_restore", "default", null, null, "0.0.0.0/0");
更新CN环境变量
在通过CN访问数据库之前,需要更新以下GMS的链接串。登录CN容器,在/home/admin/drds-server/目录下创建env/config.properties文件:
 并将新GMS的链接串信息写入其中:
并将新GMS的链接串信息写入其中:
metaDbPasswd=mGdepfbR9Te2qn+8xDeCog==
metaDbConn=mysql -h172.16.201.11 -P15295 -uadmin -pAsnoUXSV -Dpolardbx_meta_db
这里的metaDbPasswd和metaDbConn里的密码都来自于原实例信息,metaDbConn的host和port则是新GMS的leader的host和port。更新完config.properties之后,需要对CN容器进行重启。
检验恢复情况
恢复完成,恢复出了预期中的12条数据:
连接时注意使用原实例的密码
