UNI_HASH
本文将介绍UNI_HASH的使用方式。
描述
使用UNI_HASH分库时,根据分库键的键值直接按分库数取余。如果键值是字符串,则字符串会被计算成哈希值再进行计算,完成路由计算,例如HASH('8')等价于8 % D(D 是分库数目)。
分库和分表都使用同一个拆分键进行UNI_HASH时,先根据分库键键值按分库数取余,再均匀散布到该分库的各个分表上。
注意事项
UNI_HASH算法是简单取模,要求拆分列的值的自身分布均衡才能保证哈希均衡。
使用限制
拆分键的数据类型必须是整数类型或字符串类型。
使用场景
适合于需要按用户ID或订单ID进行分库的场景。
适合于拆分键是整数或字符串类型的场景。
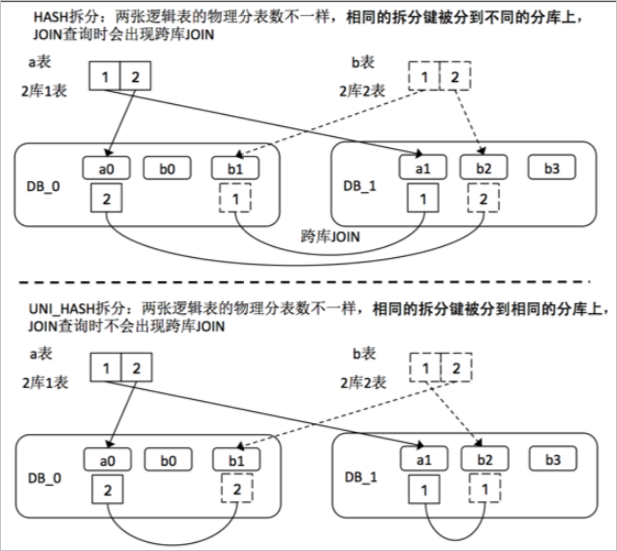
两张逻辑表需要根据同一个拆分键进行分库,两张表的分表数不同,又经常会按该拆分键进行JOIN的场景。
使用示例
假设需要对ID列按UNI_HASH函数进行分库分表,每库包含4张表,则您可以使用如下DDL语句进行建表 :
create table test_hash_tb (
id int,
name varchar(30) DEFAULT NULL,
create_time datetime DEFAULT NULL,
primary key(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by UNI_HASH(ID)
tbpartition by UNI_HASH(ID) tbpartitions 4;
与HASH的比较
| 对比场景 | UNI_HASH | HASH |
|---|---|---|
| 分库不分表。 | 此时两个函数的路由方式一样,都是根据分库键的键值按分库数取余。 | |
| 使用同一个拆分键进行分库分表。 | 同一个键值分到的分库的路由结果不会随着分表数的变化而改变。 | 同一个键值分到的分库会随着分表数的变化而改变。 |
| 两张逻辑表需要根据同一个拆分键进行分库分表,但分表数不同。 | 当两张表按该拆分键进行JOIN时,不会出现跨库JOIN的情况。 | 当两张表按该拆分键进行JOIN时,会出现跨库JOIN的情况。 |
假设有2个物理分库(DB_0和DB_1),2张逻辑表(a和b),其中a表每库1张分表,b表每库2张分表。下图展示了分别使用HASH和UNI_HASH进行拆分后,a表和b表进行JOIN的情景: